Large Language Model Connected with Massive APIs
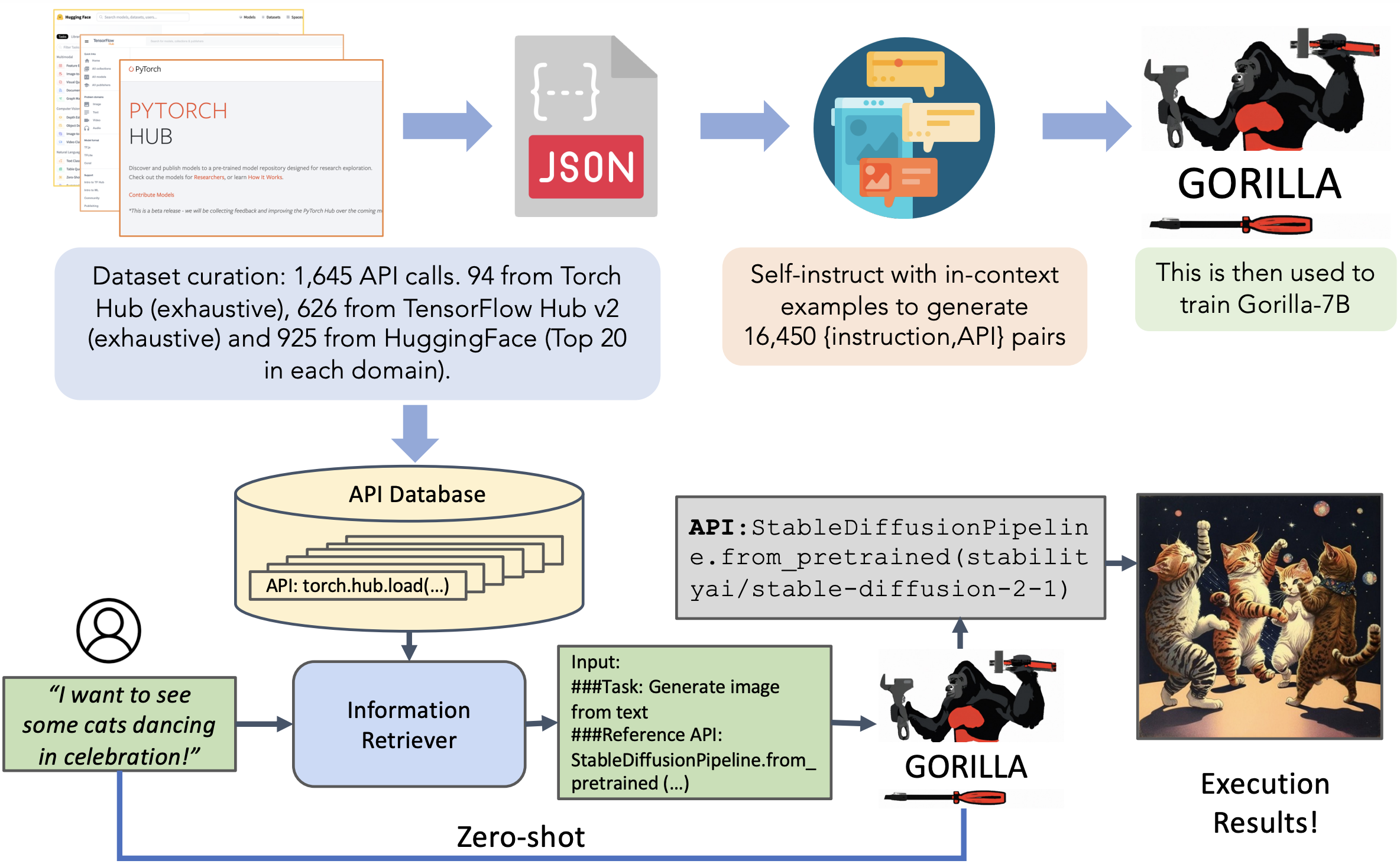
Gorilla is a LLM that can provide appropriate API calls. It is trained on three massive machine learning hub datasets: Torch Hub, TensorFlow Hub and HuggingFace. We are rapidly adding new domains, including Kubernetes, GCP, AWS, OpenAPI, and more. Zero-shot Gorilla outperforms GPT-4, Chat-GPT and Claude. Gorilla is extremely reliable, and significantly reduces hallucination errors.
Abstract
Large Language Models (LLMs) have seen an impressive wave of advances recently, with models now excelling in a variety of tasks, such as mathematical reasoning and program synthesis. However, their potential to effectively use tools via API calls remains unfulfilled. This is a challenging task even for today's state-of-the-art LLMs such as GPT-4, largely due to their inability to generate accurate input arguments and their tendency to hallucinate the wrong usage of an API call. We release Gorilla, a fine-tuned LLaMA-based model that surpasses the performance of GPT-4 on writing API calls. When combined with a document retriever, Gorilla demonstrates a strong capability to adapt to test-time document changes, enabling flexible API updates and version changes. Gorilla also substantially mitigates the issue of hallucination, commonly encountered when prompting LLMs directly. To evaluate the model's ability, we introduce APIBench, a comprehensive dataset consisting of HuggingFace, TorchHub, and TensorHub APIs. The successful integration of the retrieval system with Gorilla demonstrates the potential for LLMs to use tools more accurately, keep up with frequently updated documentation, and consequently increase the reliability and applicability of their outputs. Gorilla models and code are available LINK